현업에서 높은 수준의 결과를 원하는건 아니고 수많은 데이터 분석을 어떻게 손쉽게 할수 있을까 하는 생각에 파이썬을 시작하게 되었다. 내가 글솜씨가 없어서 구글에서 참조한 글을 적어본다.
Pandas는 데이터 분석 및 조작에 널리 사용되는 Python 라이브러리입니다. 테이블 형식의 데이터를 효율적으로 저장하고 처리할 수 있는 고성능, 사용하기 쉬운 데이터 구조(Dataframe)와 데이터 분석 도구를 제공합니다.
Pandas의 주요 특징:
- 데이터프레임(DataFrame): Pandas의 핵심 데이터 구조로, 행과 열로 이루어진 테이블 형식의 데이터를 다룰 수 있습니다. 엑셀 스프레드시트와 유사하다고 생각하면 됩니다.
- 데이터 읽기 및 쓰기: CSV, Excel, SQL 데이터베이스 등 다양한 형식의 데이터를 읽고 쓸 수 있는 함수를 제공합니다.
- 데이터 선택 및 필터링: 특정 조건을 기반으로 데이터를 선택하고 필터링하는 다양한 방법을 제공합니다.
- 데이터 정렬 및 그룹화: 데이터를 특정 열을 기준으로 정렬하거나 그룹화하여 분석할 수 있습니다.
- 결측값 처리: 데이터에 존재하는 결측값을 찾아서 처리하는 기능을 제공합니다.
- 데이터 병합 및 변형: 여러 개의 데이터프레임을 병합하거나, 데이터프레임의 구조를 변경하는 등 다양한 데이터 변형 작업을 수행할 수 있습니다.
- 통계 분석: 평균, 표준 편차, 상관 관계 등 다양한 통계량을 계산하는 함수를 제공합니다.
Pandas는 데이터 분석 작업을 수행하는 데 매우 유용한 도구입니다. 데이터 과학자, 데이터 분석가, 프로그래머 등 데이터를 다루는 다양한 분야에서 널리 사용됩니다.
읽어보면 주요특징에 나오는 특징들이 데이터 처리에 있어 매우 중요한 부분이다. (몇 번 실습해본 결과 나의 생각임)
지금부터 예제 코드를 볼텐데 직접 Raw Data를 읽어서 처리하는것은 나중에 다룰 예정이고, 여기에서는 pandas 기본만 볼 생각이다.
먼저 "data"를 DataFrame 형태로 생성하고, 구조를 살펴보자. 엑셀에서 보던 'Row', 'Column'은 동일하고 대신 데이터 처리를 위해 필요한 '열이름(columns name)'과 '색인(index)'을 알아두면 된다. 이 개념을 이용하여 데이터 처리에 활용된다.

예제를 보면(위에 설명한 구조와 동일함), 데이터 구조를 확인할 수 있는 다양한 예시가 있다.
- df.index : 색인 확인
- df.columns : 열이름 확인
- df.shape : 행/열 구조 확인
- df.head() : 최초 5개의 행 확인
- df.tail() : 마지막 5개의 행 확인
- df.describe() : 통계정보요약
이외에 다양한 방법들이 있으니 익수하게 해두면 좋다.



데이터 선택 및 필터링, 데이터 정렬 및 그룹화, 지정 데이터 가져오기 등은 아래 예제를 활용하자.
행 값은 이름이 아니라 숫자로 적어서 값을 가져오는 방식이 열과는 다르다.



sort_values(), groupby()에 대한 부연 설명은 아래를 참조하자.
df.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
- by: 정렬 기준이 될 열 이름 또는 열 이름 리스트.
- axis: 정렬할 축 (0: 행, 1: 열). 기본값은 0.
- ascending: True이면 오름차순, False이면 내림차순 정렬. 리스트로 여러 열을 지정하면 각 열에 대한 정렬 방식을 개별적으로 설정할 수 있음.
- inplace: True이면 원본 DataFrame을 직접 변경하고, False이면 정렬된 새로운 DataFrame을 반환함. 기본값은 False임.
- na_position: 결측값(NaN)의 위치를 지정함. 'first'는 앞으로, 'last'는 뒤로 배치함.
- ignore_index: True이면 정렬 후 인덱스를 0부터 다시 설정함
df.groupby(by, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
- by: 그룹화 기준이 될 열 이름, 열 이름 리스트, 함수, 또는 딕셔너리.
- axis: 그룹화할 축 (0: 행, 1: 열). 기본값은 0
- as_index: True이면 그룹화된 열을 인덱스로 사용하고, False이면 일반 열로 유지함
- sort: True이면 그룹을 정렬함
- dropna: True이면 결측값(NaN)이 포함된 그룹을 제외함
여기부터 끊고 갈까 했는데.. 그냥 한번에 적어본다. 결측치 확인하는 방안과 데이터 검색하는 방식에 대한 내용이며 데이터 일치여부, 대소비교, 조건식 검색 등이 있다.
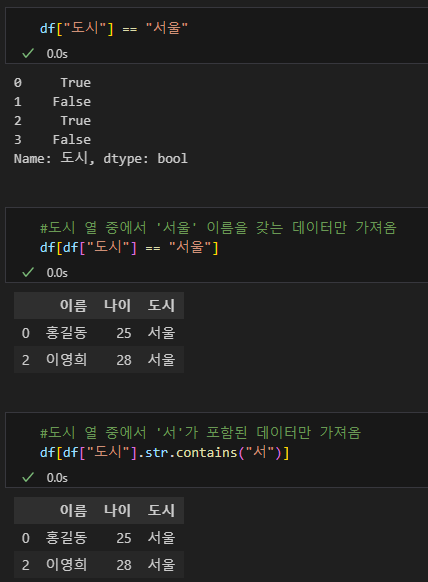

결측치는 값이 없음을 나타내며 NaN이라고 표시가 된다. (데이터가 아예없음을 의미하며 0은 데이터로 인식) 데이터 분석시 이러한 결측치를 제거해줘야 정확한 결과를 얻을 수 있게 되는데 min, max, avg 등 어떤 값을 넣어야 원하는 결과를 얻어 낼수 있을지는 보통 경험으로 결정한다고 한다.(?)

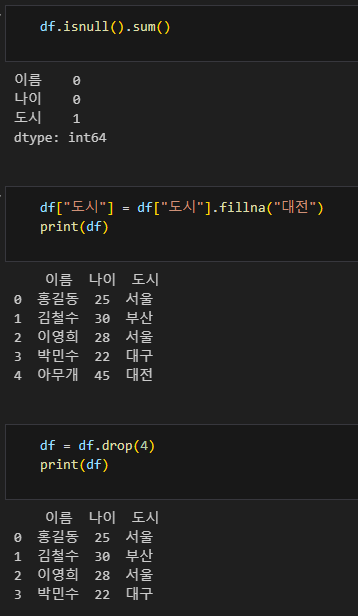
- df.isnull() : 결측치 찾아줌
- df.isnull().sum() : 결측치 합산 결과 알려줌
- df["도시"].fillna("대전") : df 데이터프레임의 "도시" 열에서 모든 결측값(NaN)을 "대전"이라는 값으로 채움
'아빠 > 취미' 카테고리의 다른 글
| 가상화폐 - 스테이블코인(나름 화폐전쟁?) (3) | 2024.11.26 |
|---|---|
| 가상화폐 - 공부 (개념/용어) (0) | 2024.11.26 |
| 파이썬 속성 - while(), 함수 (0) | 2024.08.17 |
| 파이썬 속성 - if(), for() (0) | 2024.08.04 |
| 파이썬 속성 - 리스트, 딕셔너리, Range (1) | 2024.08.04 |



